
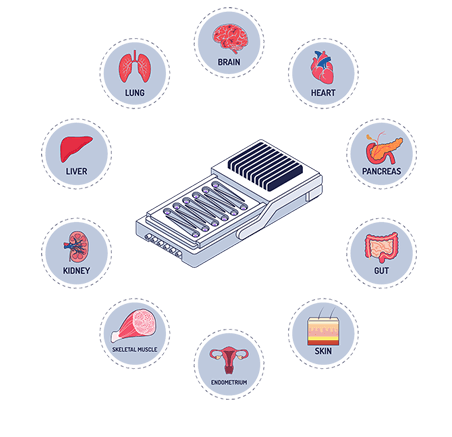



















nuclera 高通量微流控蛋白表達篩選系統
英國nuclera公司由劍橋大學的博士生們于2013年創立。在撰寫論文期間,他們發現蛋白質難以獲取的問題是生物學領域的首要障礙和關鍵瓶頸。他們著手解決蛋白質難以獲取的問題,以期改善人類健康狀況。這一驅動力符合公司的愿景,即打造出一個從構思到蛋白質的原型設計系統,以減少在藥物發現計劃中獲得靶蛋白的時間和障礙。









